
そもそもなぜ「データ分析」が重要なのか
データのお仕事の話に移る前にそもそもなぜ「データ分析」が重要かについて、筆者櫻井の個人的な見解を説明しておこうと思います。「組織としてデータ分析が重要」という話と「個人としてデータ分析が重要」という話の2つに大きく分けて記載させていただけると幸いです。
この部分については意見が分かれる箇所であるため、1意見として読んでもらいつつ、違和感や意見等あれば是非コメント等送っていただき、一緒に議論させていただけると幸いです。
【組織から見たデータ分析】「技術の進歩」と「サービスの均一化」
まず「データ分析」が社会的バズワードになり重要視され始めた背景として、「技術の進歩」と「サービスの均一化」という大きな流れがあると考えています。前者は言葉の通り「技術の進歩」によって特にIT関連のサービスは、より高度なものがより簡単に実現できるようになりました。一方その影響で起きた現象の一つとして後者の「サービスの均一化」があると考えています。サービスの開発ハードルが下がったことにより様々な人が様々なサービスを生み出すようになり、その中で生き延びたサービスは機能面などが似通ってきて差分をつけることが難しくなっていると考えています。
そんな中差別化を行う際に上げられた項目の一つが「データ」であると筆者は考えています。特に既存の企業しかもち得ない資源であるため、先行優位性をさらに活かす手段として検討される機会が多いのだと考えています。
差別化要因例(=他社の模倣が困難)
- ブランドやデザイン
- より高度な技術
- 企業活動で得られるデータ
- …
【個人から見たデータ分析】平等に利用可能な知見・経験
一方個人から見たデータ分析は「組織から見たデータ分析」で上げたような「差別化要因」としての強みがあまり感じられず、「平等に利用可能な知見・経験」としての意味合いが強いと考えています。仕事を行う上で自分の考えを通すためには、基本的に論理的根拠の説明が必要とされますが、不確定要素の多いビジネスでは演繹法によって物事が語られることはほぼなく、多くが帰納法的に説明されるため知見や経験が重要となります。その場合「経験の多さ」が重要であることは言うまでもなく、「平等に利用可能な知見・経験」として利用できるデータ分析が重要だと言われる理由だと考えています。
論理的根拠の説明
- 帰納法:今までの知見・経験から法則を導き出し説明を行う
- 演繹法:正しいとされる前提を組み合わせて説明を行う
AIが重要なわけではない?
ではニュースで騒がれた「AI」はどのように関連してくるのかについても記載しておこうと思います。個人的にAIは現時点では差別化要因における「より高度な技術」に分類されるものだと考えています。そのため重要な差別化要因の一つであり、現にその技術を適切に用いることで成功しているサービスも多く存在すると考えています。ただ注意が必要なのは「より高度な技術」は差別化要因となり得るが、自社にとって優位性があるかどうかは別途検討が必要であるという点です。
一方「企業活動で得られるデータ」は基本的にほぼすべての企業において得られるものであり、ほぼ全ての企業が利用することのできる資源になります。その点において「データ分析」と「AI」は分けて語られるべきだと考えているのが個人的な見解です。
AI(機械学習を含む)が重要なわけではない?:「分析と予測」「データ価値濃度とコスト」
ただ技術的にはAIに複雑なモデルなど機械学習も含む場合は、「データ分析」の利用目的と「AI(機械学習を含む)」の利用目的が似てくるケースもでてきます。(そもそもAIの定義をちゃんとしようという話が別の問題としてありますが…)その場合個人的に意識すべきは「分析と予測」と「データ価値濃度とコスト」だと思っています。
| 分析と予測 | 利用するデータ価値濃度 | コスト | |
| データ分析 | 分析:情報・知見を抽出 | 濃い | 小 |
| AI(機械学習を含む) | 予測:結果の数値を出す | 薄い~濃い | 大 |
分析と予測
前者の「分析と予測」は利用用途の部分で、データを使って何を行うかの部分になります。分析は新しい「情報・知見を抽出」する作業であるのに対し、予測は「結果の数値を出す」する作業になるため、利用用途に違いがあります。予測で得られる結果の利用用途は限定的であることが多く、例えば100%来週の売上が予測できたとしても、なぜ売上が変動するかといった「情報・知見を抽出」はできない可能性が高いです。そのため基本的に予測を行う場合は、得られる結果が直接プロジェクトの目標と紐付いている必要があります。
データ価値濃度とコスト
後者の「データ価値濃度とコスト」は利用用途が予測であり、「データ分析」と「AI(機械学習を含む)」どちらで行うべきか検討する際に用います。ここで「データ価値濃度」はデータから得られる情報量を指しており、例えば「明日の売上予測」において「今日の売上」はデータ価値の濃度が濃く、「アリゾナ州の湿度」はデータ価値の濃度が薄いといったイメージです。
基本的にデータ分析はデータ濃度が比較的濃いものにしか用いることができない一方、人やお金のコストは小さいため手軽に行うことができます。そのため目的を達成するために効率的な方法を検討するという意味で、扱うデータの価値濃度が濃ければデータ分析を行い、薄ければAI(機械学習)を検討すればよいのではというのが個人的な見解になります。(その意味でデータ分析を行ってこなかった企業がいきなりAIを検討するのは、価値濃度が濃くデータ分析で色々予測が立てられるにも関わらず、よりコストの掛かるAIを使っている点で効率が悪いと捉えています)
データのお仕事とはなにか
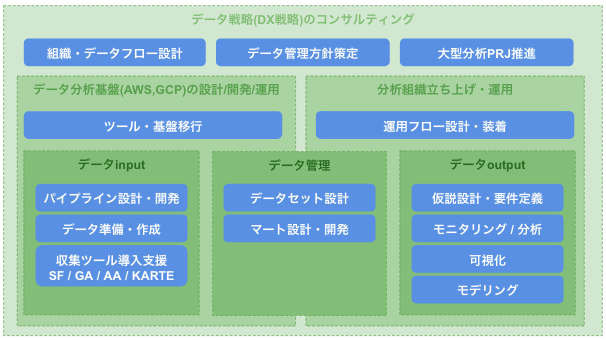
前段が長くなってしまいましたが、こういったデータの重要性増加に伴い「データのお仕事」への需要も高まってきています。ただ「データのお仕事」といっても多岐にわたっているため、弊社がまとめた上記図を使ってそれぞれ説明していこうと思います。
データinput
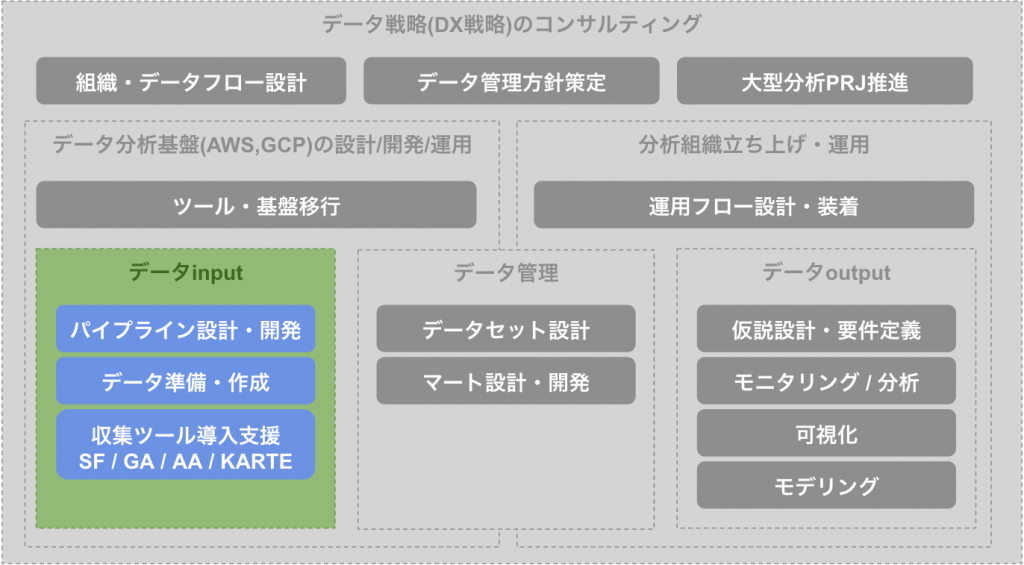
データ分析を行う上でまず重要な仕事がデータinputの箇所になります。「データの仕事」というとビジネスに近いデータ分析やモデリングなどが想像しやすいですが、中長期的なデータ分析の土台としてデータ資産を貯めているという意味では、データ戦略において一番と言ってよいほど重要な箇所になっています。データが無ければ優れた分析手法やモデリングも効果が出ず、逆にデータ価値濃度が高いデータが取れていれば基礎分析だけでも大きな示唆を得ることができます。
パイプライン設計・開発
データinputでまずよくある手法が、特定サービスやシステムで発生したデータをパイプラインを用いて分析基盤まで連携する方法になります。例えばオンプレサーバーのPostgreSQLに溜まっているユーザー情報を、パイプラインを用いてAmazon Redshiftに連携するケースなどです。パイプラインを設計する際には開発と同じように要件定義(機能要件・非機能要件)から設計を行い、その後開発を進める必要があります。近年各種クラウドサービスからマネージドサービスが出ていたり、troccoといったサードパーティサービスがでてきたりと新しい技術が次々と出てきている領域でもあります。
データ準備・作成
データinputの次の手法が、データを別の場所から移すのではなく作成してそのまま入れる方法です。例えば日本郵便株式会社のAPIから郵便番号マスターテーブルを作成したり、Google Sheetsなどから商品テーブルを作るケースなどです。データ取得処理と分析基盤へ連携する処理を分ければ後者をパイプラインと定義することもできますが、システム設計が大きく異なることが多いためパイプラインとは分けています。こういった処理は個別での開発になることが多く、運用コストを下げるためにどの程度汎用化させるかといった観点がポイントになってきます。
収集ツール導入支援
最後に収集ツールを用いたデータの収集方法があります。こちらは様々な企業で利用されているもので、ツール単体で分析基盤への連携ができたり、別途パイプラインが必要なものなど様々なツールが存在しています。これらツールの支援では利用方法の設計が主な内容となっており、例えばGoogle Analyticsにおけるログ設計(どのページでどういった情報をとるべきか)などがあります。代表的なツールとしては以下のようなツールが存在します。
- Salesforce:顧客関係管理システム
- Google Analytics / Adobe Analytics:Webページのアクセス解析サービス
- KARTE:CX(顧客体験)プラットフォーム
データ管理
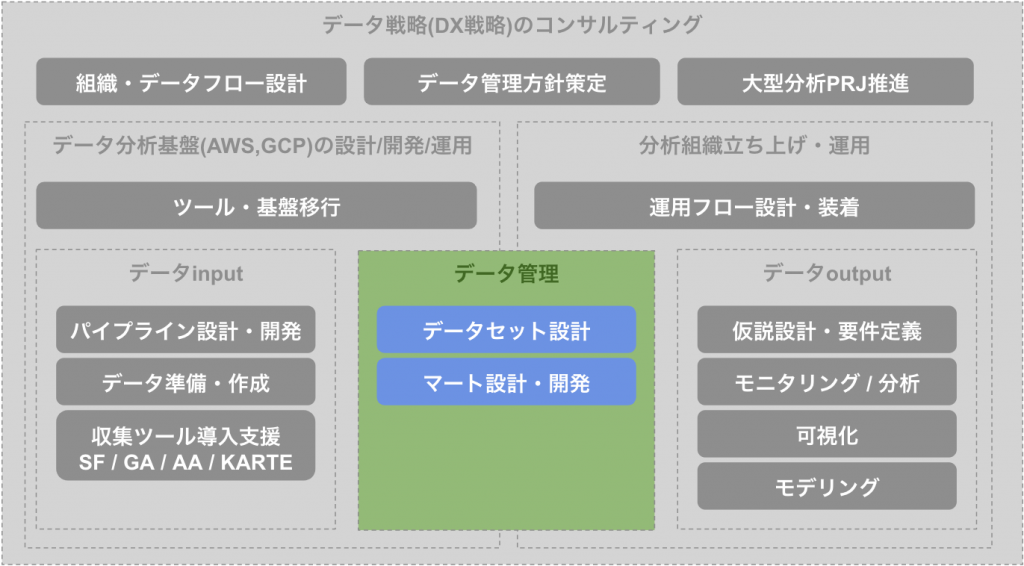
次にデータ分析を行う上で必要な仕事がデータ管理の箇所になります。こちらも中長期的に重要にな要素であり、データのセキュリティや運用・管理コストに大きく影響を与える箇所になっています。パイプラインと違い利用方法や組織体制によって設計が大きく変わってくる箇所のため、利用者へのヒヤリングによる要求調査も重要となってくる場所でもあります。
データセット設計
データセット設計は分析環境におけるデータ格納場所を決める作業になります。「データ基盤の運用・管理コスト」といったシステム側の目線と、「データの可用性」といった利用者側の目線、また「データのセキュリティ」といったデータ管理者の目線など様々な観点を考慮した設計が必要となります。例えば以下表のようにどれかに偏りすぎると他の箇所で不自由な点が出るケースが多いです。(なお設計例に記載した内容はあくまで要求・要件がない状態で作成した例であるため、実際の設計時にそのまま利用しないようお願いいたします)
| 設計例 | システム側 不自由例 | 利用者 不自由例 | データ管理者 不自由例 | |
| システム を優先 | 連携ごとに データセットを作成 | – | 利用時に、 複数データセットを 見る必要がある | データ内容ごとに 閲覧権限の調整が 難しい |
| 利用者 を優先 | 利用用途ごとに データセットを作成 | 用途が違うが 内容が同じデータが 複数でてくる | – | データ鮮度やSLAが 異なるデータが 一箇所で混ざる |
| データ管理者 を優先 | 組織図に合わせて データセットを作成 | 内容が同じデータが 複数でてくる | 他チームの データ再利用が しづらい | – |
実際の現場においては気にする目線や観点の数は例と比べて増えたり減ったりし、また重要度も変わってくるため要求・要件を正確に整理することが重要となってきます。
マート設計・開発
上記データセット設計の次に必要な作業がマート設計・開発になります。
データマート (Data Mart) は、データウェアハウスの中から特定の目的に合わせた部分を取り出したもの。通常は利用部門が利用目的に合ったデータのみを所持するものである。
https://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%9E%E3%83%BC%E3%83%88
マート作成は必ずしも必須のものでは有りませんが、ユーザー目線の要求を実現するために基本的に必要となってくるものになります。例えば売上や購入者情報、店舗情報、ECサイト行動ログなどが、正規化や取得元の影響でばらばらになっていた際に、それらをユーザーごとに集計したマートを作っておくことで、ユーザー側の使いやすさは大きく向上します。データマートはどの程度汎用化させるかの加減が重要であり、汎用化しすぎると使いにくくなり、汎用化をあまりしないとマートの乱立を引き起こします。そのため「データチームが管理する汎用化マートと特定用途に応じたマートでわける」といった、用途別に保守コストを分ける設計を行うケースも少なく有りません。
データoutput
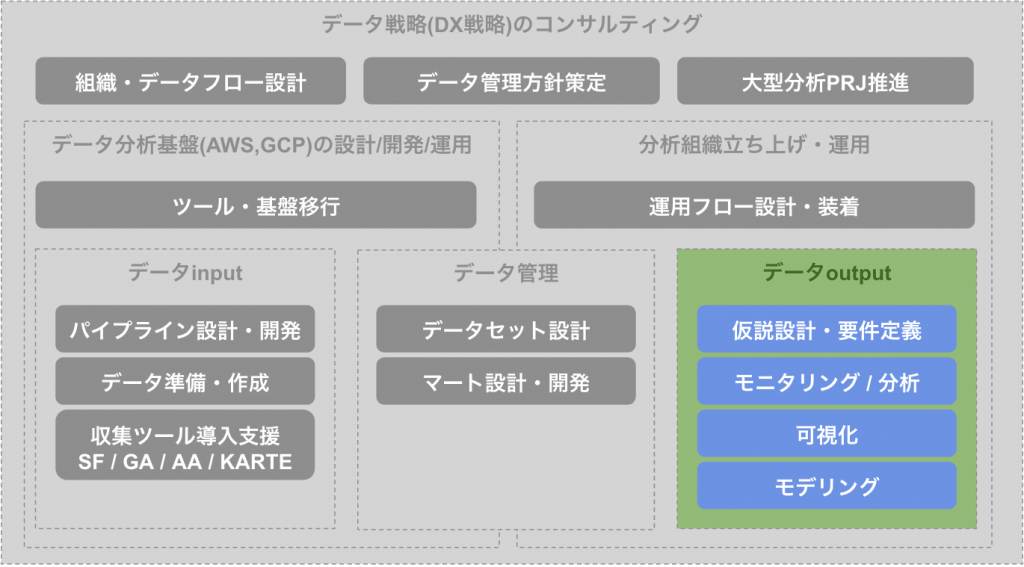
最後が「データのお仕事」の最終目標であるデータoutputの箇所になります。他2つと比較すると中長期的な目線が少なく、短期的に案件に応じてデータから適切なoutputを抽出することが求められる箇所になります。またinput・管理と比較してビジネス側と一番近い箇所でもあるため、分析の技術の他にビジネスドメインへの理解がより求められる箇所でもあります。データを価値に変える部分になるため非常に重要な部分であり、ここで価値を出せない場合は前段のinput・管理を含めてデータ戦略を見直す必要が出てきます。
仮説設計・要件定義
データoutputの箇所においてまず重要になるのが、データではなく仮説設計や要件定義となっています。なぜなら近年データ取得可能量は飛躍的に伸びており、「ひとまずデータをみてみよう」となった際のコストが膨大になってきているためです。そのためデータを見る前に例えば「アンケート結果から売上が減っている原因は20代女性の購買行動変化によるものでは?」といった仮説設計、「20代女性の購買行動変化は売上ログとユーザーマートの**データを使うことで確認できる」といった分析要件定義が重要となってきます。イメージとしてはビジネス課題とデータの架け橋を行う作業になります。
モニタリング / 分析
仮説設計やビジネス要件ができた次にでてくる作業が分析やモニタリングになります。分析仮説に沿って行った分析によって示唆を抽出し、必要に応じて特定の数値を定期的に確認する作業をモニタリングと定義しています。例えば上記の「20代女性の購買行動変化」の分析を行った際に「20代女性の平均購入点数」がビジネス上重要な指標であると判明した後、月次で「20代女性の購入点数月次平均」を見るシステムや運用を整える作業がモニタリングになります。
- 分析:データで仮説の検証を行う
- モニタリング:検証済みの仮説に沿って、正常性の確認を行う
このあたりからデータを見る時間が長くなってきますが、往々にしてデータ分析やモニタリングの目的が忘れられて形骸化するケースが発生してしまうため、「なぜそのデータを見る必要があるか」が常に分かる状態を保つことが重要だと考えています。

可視化
また分析やモニタリングの手法の一つとして可視化が行われるケースもあります。データ単体の分析やモニタリングと比較すると、開発・運用・管理などのコストが高い一方、得られる情報量が多い点が主な特徴になります。例えば売上の特徴量をデータから捉える場合は、「日別の売上平均値・中央値・標準偏差・四分位範囲..」などの特徴量をそれぞれ見る必要がありますが、可視化で捉える場合はそれらを「日別の箱ひげ図」などを用いることで感覚的に理解することができます。ただ可視化された情報はわかりやすい反面データ定義や解釈などが誤解されることも多くあるため、運用方法を想定して開発を行う必要があります。
モデリング
最後がAI(機械学習含む)などともつながるモデリングになります。モデリングは分析やモニタリングとは違って示唆を抽出するのではなく、売上予測値などの数値を算出するモデル(≒計算式)を作成する作業になります。例えばモデリングによって「先1ヶ月の売上予測が判明」したとしても、「先1ヶ月の売上を上げる施策」はわからない場合があります。一方で弁当売れ残りをなくしたいプロジェクトなど予測値自体が直接利用可能な場合においては、「先1ヶ月の弁当販売予測」は直接発注量調整に使え大きな価値があります。
ただモデリングの利用用途が設計できた場合においても、「算出するモデル(≒計算式)」にどの数値を使うか(=説明変数)の選定が重要であることを考えると、まず分析やモニタリングによってデータと事業の関係を明らかにする作業を行う必要があると思われます。
まとめ
今回「データのお仕事」という定義が曖昧な内容について、なぜ重要であるかと具体的にどういった内容であるかを説明させていただきました。冒頭でも記載させていただいたとおり1意見として読んでもらいつつ、違和感や意見等あれば是非コメント等送っていただき、一緒に議論させていただけると幸いです。今後「データ」に興味を持った方が今後を考える際の参考に少しでもなれば幸いです。

コメント
Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.
Commenter avatars come from Gravatar.