
本記事の内容
Amazon S3に存在しているデータをBigQueryに定期的に自動連携する方法を説明します。
成果物イメージ
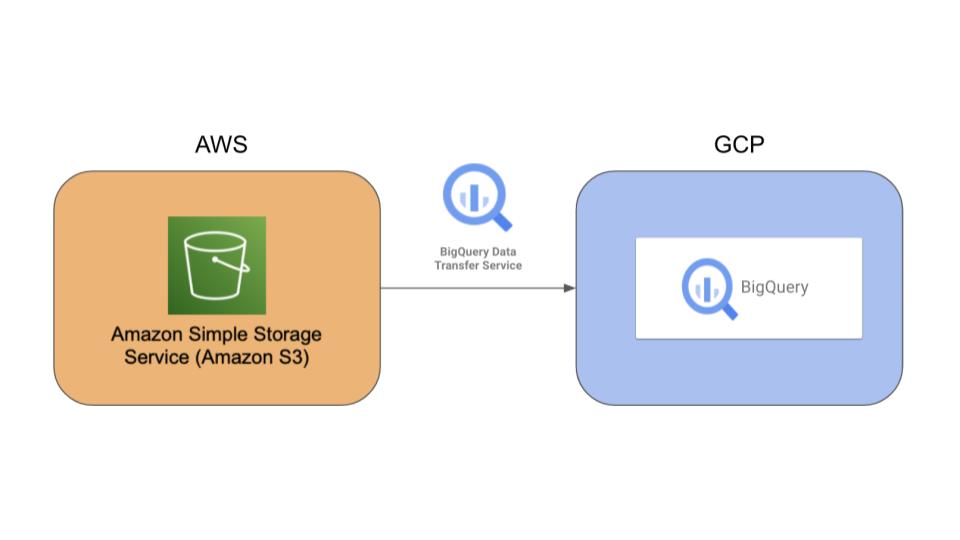
Amazon S3に保存されているデータをBigQueryにBigQuery Data Transfer Serviceを用いて連携します。
BigQuery Data Transfer Service は、あらかじめ設定されたスケジュールに基づき、BigQuery へのデータの移動を自動化するマネージド サービスです。そのため、アナリティクス チームが BigQuery データ ウェアハウス基盤を構築する際にコードの作成はまったく必要ありません。
https://cloud.google.com/bigquery-transfer/docs/introduction?hl=ja
想定要件
必須要件
- Amazon S3に蓄積されるデータをBigQueryに連携したい。
- 日時でBigQueryのデータの更新を行いたい。
その他要件
- なるべくマネージドサービスを使いたい。
- 日時で新規作成・更新されるファイル数は10000以下である。
- BigQuery Data Transfer Serviceの1回のデータ転送の上限が10000ファイルであるため。
実際に構築してみましょう
AWS側での操作
Amazon S3にデータを用意する
まずは Amazon S3 に、元データをアップロードしましょう。
Amazon S3 にデータをアップロードする前に、 Amazon S3 にバケットを作成します。
今回はバケットに「sample-bucket-sink-capital」という名前を付けています。
作成したバケットにファイルを置きます。
s3://sample-bucket-sink-capital/ah22wkekym6jthzr6xkmraxste.json.gzBigQuery が対応しているファイルはCSV, JSONL(JSON(改行区切り))、Parquetなどです。詳しくは公式ドキュメントを参照ください。
https://cloud.google.com/bigquery/docs/batch-loading-data
BigQueryがAmazon S3にアクセスするためのキーを作成する
次に Amazon S3 に、アクセスするためのキーを作成しましょう。
AWS Identity and Access Management (IAM) にて「s3-to-bigquery」という名前のユーザーを作成し、「アクセスキー – プログラムによるアクセス」を選択します。
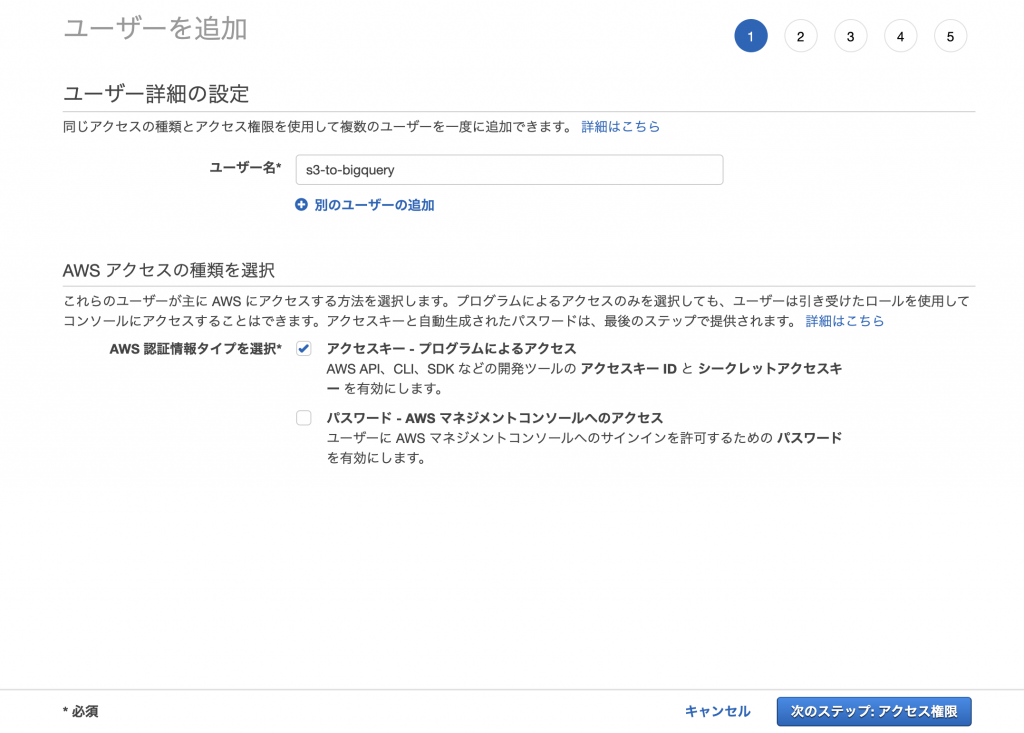
「既存のポリシーを直接アタッチ」から「AmazonS3ReadOnlyAccess」を選択します。
ユーザーの作成時に表示された、アクセスキー IDとシークレットアクセスキーは後ほど使います。
※シークレットキーは、作成時に表示またはダウンロードできるのみです。既存のシークレットキーを正しく配置できなかった場合は、新しいアクセスキーペアを作成してください。
GCP側での操作
BigQuery のAPIを有効にする
まずは、BigQuery のAPIを有効にしましょう。
- BigQuery Connection API
- BigQuery Data Transfer API
- BigQuery API
BigQuery のデータセットを作成する
BigQueryのデータセット を作成しましょう。
「sample_data_lake」という名前のデータセットをTerraformで作成します。
resource "google_bigquery_dataset" "dataset" {
dataset_id = "sample_data_lake"
friendly_name = "sample_data_lake"
description = "AWSのデータを連携するデータセット"
location = "asia-northeast1"
}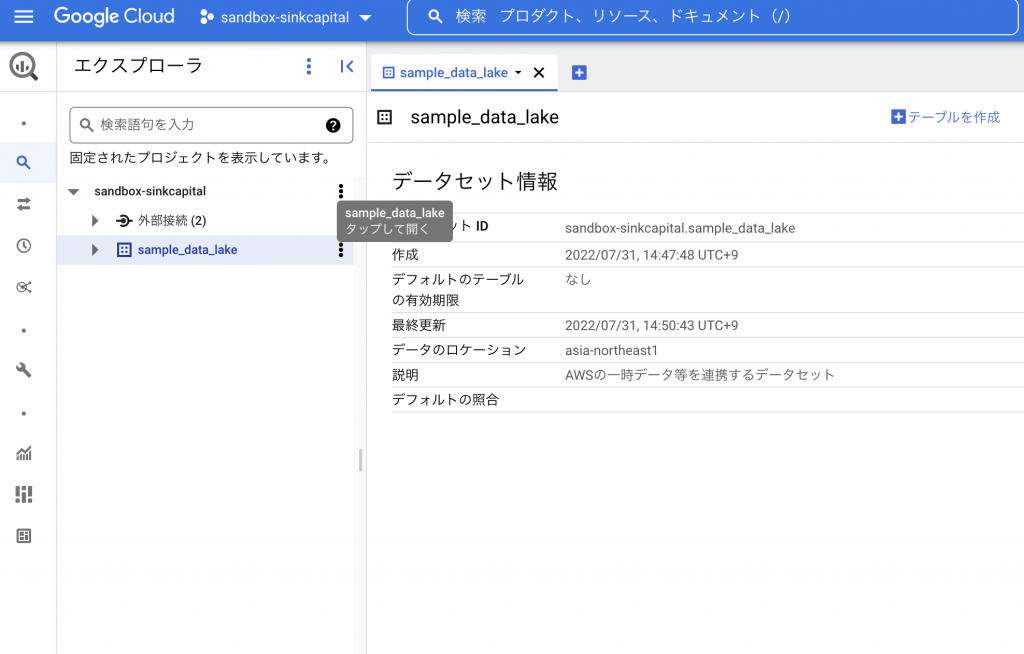
「sample_data_lake」という名前のデータセットが作成されたことが確認できます。
BigQuery のテーブルを作成する
BigQuery のテーブルを作成しましょう。
「sample_table」という名前のテーブルをTerraformで作成します。
resource "google_bigquery_table" "sample_table" {
dataset_id = google_bigquery_dataset.dataset.dataset_id
table_id = "sample_table"
schema = <<EOF
[
{
"fields": [
{
"fields": [
{
"mode": "NULLABLE",
"name": "S",
"type": "INTEGER"
}
],
"mode": "NULLABLE",
"name": "primary",
"type": "RECORD"
},
{
"fields": [
{
"mode": "NULLABLE",
"name": "S",
"type": "STRING"
}
],
"mode": "NULLABLE",
"name": "secondary",
"type": "RECORD"
}
],
"mode": "NULLABLE",
"name": "Item",
"type": "RECORD"
}
]
EOF
}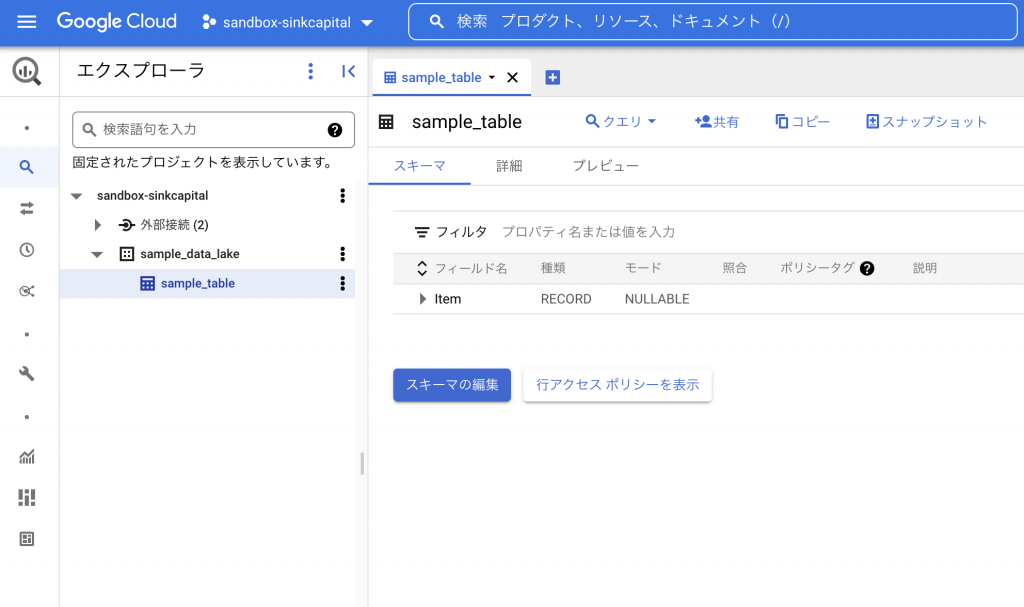
「sample_table」という名前のテーブルが作成されたことがわかります。
Tips
テーブル数が多い場合など、スキーマ情報を定義することが少し手間かと思います。その場合は、以下の方法でスキーマ情報をJSON形式にて取得できます。
1. s3のデータファイルをローカルにダウンロードする。
2. BigQuery にテーブルを作成する。
BigQueryコンソールにて【テーブルの作成】→ソースをアップロードにする。
スキーマを自動検出にする。
3. テーブルのスキーマを取得する。
Cloud shellにて、2で作成したTABLE_NAMEのスキーマをJson形式で取得する。
$ bq show --schema --format=prettyjson DATASET_NAME.TABLE_NAME
Amazon S3からBigQuery へのデータ転送を設定する
Amazon S3からBigQuery へデータを連携するためにBigQuery Data Transfer Serviceを設定しましょう。
「data_transfer_s3_to_bq (by terraform)」というデータ転送をTerraformで作成します。
毎日20:00(UTC)に実行されるように設定します。
data "google_project" "project" {
}
resource "google_project_iam_member" "permissions" {
project = data.google_project.project.project_id
role = "roles/iam.serviceAccountShortTermTokenMinter"
member = "serviceAccount:service-${data.google_project.project.number}@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com"
}
resource "google_bigquery_data_transfer_config" "s3_to_bq" {
depends_on = [google_project_iam_member.permissions]
display_name = "data_transfer_s3_to_bq (by terraform)"
location = "asia-northeast1"
data_source_id = "amazon_s3"
schedule = "every day 20:00"
destination_dataset_id = google_bigquery_dataset.dataset.dataset_id
params = {
destination_table_name_template = google_bigquery_table.sample_table.table_id
data_path = "s3://sample-bucket-sink-capital/ah22wkekym6jthzr6xkmraxste.json.gz"
access_key_id = var.aws_access_key
secret_access_key = var.aws_secret_key
file_format = "JSON"
ignore_unknown_values = "true"
}
}
ここで、先ほど「BigQueryがAmazon S3にアクセスするためのキーを作成する」で作成したアクセスキー IDとシークレットアクセスキーを使用します。
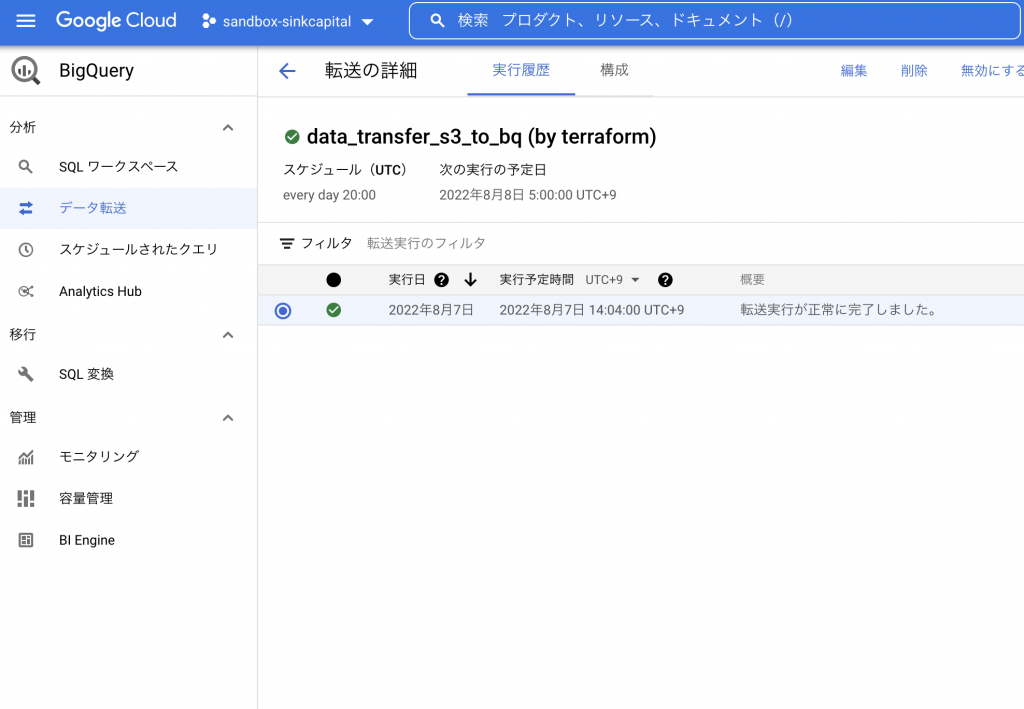
「data_transfer_s3_to_bq (by terraform)」というデータ転送が正常に実行されたことが確認できます。
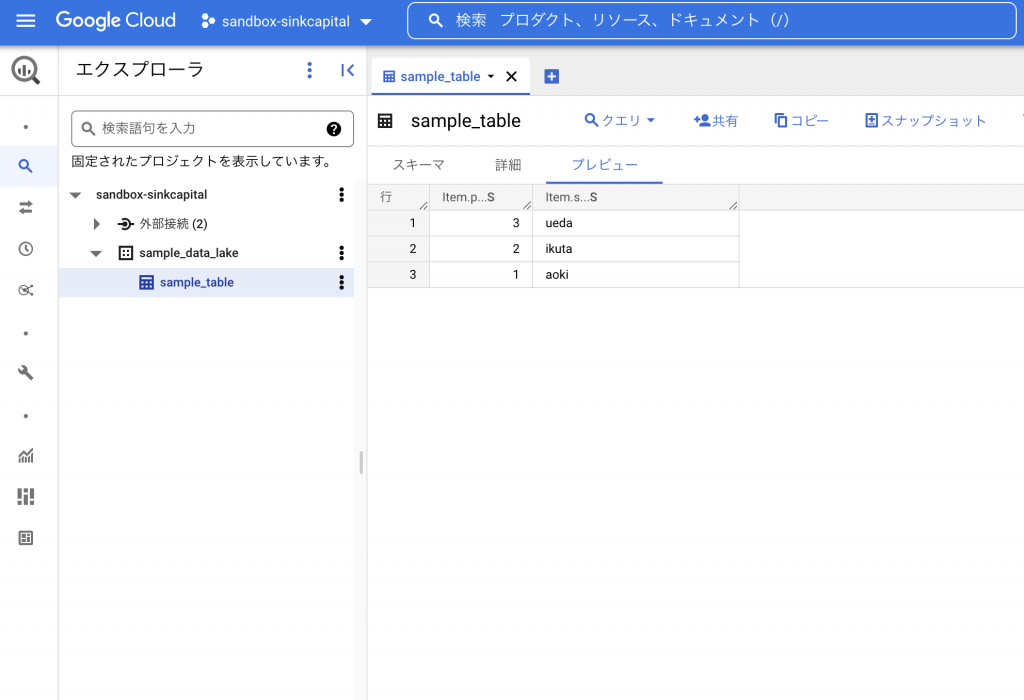
また、「sample_table」という名前のテーブルにデータが転送されたことがわかります。
これで、毎日20:00(UTC)にS3に新規作成・更新されたファイルがBigQueryに転送されるようになりました。
まとめ
Amazon S3 のデータを BigQuery のテーブルに連携することができました。本記事では、BigQuery Data Transfer Serviceを用いましたが、Storage Transfer Serviceを用いて一旦 Cloud Storageに 入れておく方法もあります。

こちらは、1時間に1回データが転送されるので、BigQuery Data Transfer Serviceでは24時間に1回でシステム要件合わない場合は、検討されると良いと思います。
また、最近リリースされたBigQuery Omni では、直接Amazon S3のデータに対してBigQuery 分析を行うことができます。リージョンが制限されていたりと、まだまだ使いづらい部分はありますが選択肢の一つになるのではないでしょうか。
BigQuery Omni は、BigQuery アナリティクス エンジンをデータが存在する場所に移動します。これにより、データの移動やコピーを行わなくても、データにアクセスして分析できます。クラウド間でデータを移動し、クロスクラウド転送を使用してクラウド間でデータを結合することもできます。
https://cloud.google.com/bigquery/docs/omni-introduction?hl=ja


コメント