
生データとは?
生データ(英:raw data)とは、集計や処理などの加工前のデータのことです。生データがあるからこそ後からでもデータ整備を行えます。一方データを見やすくするためにカラム名を和訳したものなどは、加工データに該当します。
なぜ生データを見る必要があるか
中身を知らないデータは解釈を間違えることがあります。
軸の把握
例えば、コンビニの売上に関する分析を行ったとします。曜日や時間といった軸は思い浮かびやすいですが、生データを見ることで天気や性別などの新たな分析軸があることがわかり、それらが売上と強い相関を持つといった、新たな結果が見えてくる可能性があります。これは、事前に生データを見て、どのような軸が存在するか確認しながらレコードを見ることで防げるでしょう。
PKを捉える
主キーを見間違えると間違いを生む可能性が高いです。売上データで、1注文ごとに1レコードあると思っていたが、実際は1注文に複数のレコードがあった場合など、集計方法が変わってきます。
欠損値の確認
特定のカラムにNULLが含まれていて、データ欠損している場合があります。例えば、商品別の売上集計をしようとした時に、複数の商品IDがnullになっていると、実際の売上より数字が小さく出てしまいます。このような事を防ぐために、生データを見て欠損値がないか確認する必要があります。
データを見る際の注意点
データ量
- 定量的な解析を行う場合には、十分なデータ量が必要になります。例えば、アクセスログから何か解析を行う場合、数件程度のログでは正確な傾向を掴むことができません。
- データ量によってとり得る手法や結果の解釈が変わります。データ量が少ない場合は、外れ値や異常値がノイズとなり分析の妨げになるので、それらをどう扱うか考えなければなりません。
データの種類や形
- そのデータが既に加工されたデータの場合、加工者の意図があるデータとなります。また、データというと上記のような定量的なデータを想像しがちですが、アンケートなどに書かれた文字などの定性的なモノもデータの1つです。
データの見方
準備
- 【パイプライン入門】spreaad sheet to BQを参考にデータを準備
サンプルSQL
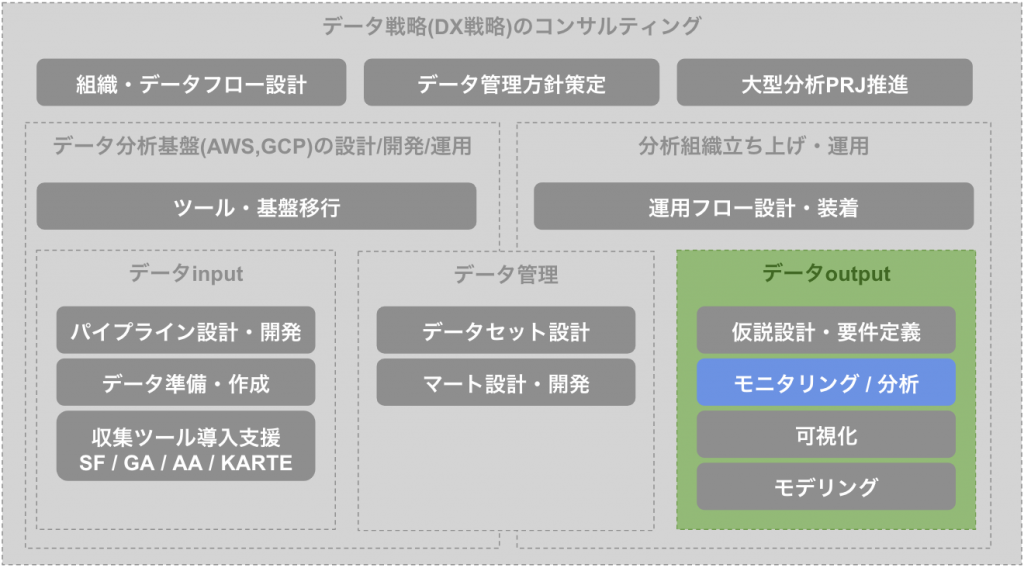
まずは10件、全カラムをSELECTしてください。
SELECT *
FROM `sample-90112.manabiba.sales`
LIMIT 10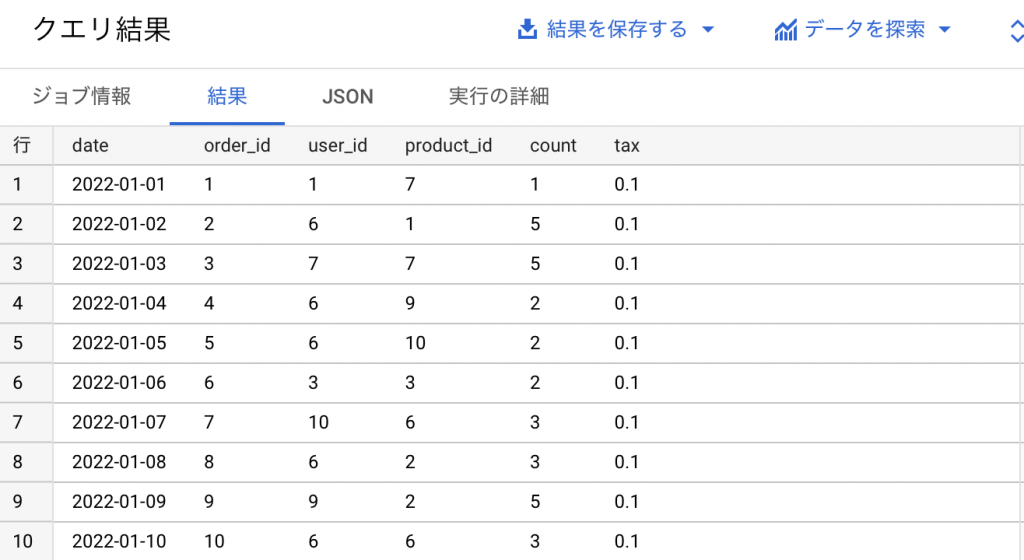
「SELECT * 」で全カラムを取得し、「LIMIT」で取得する行数を限定します。
order_idとproduct_idを組み合わせることで、データを一意に識別できるので、「order_id+product_id」で複合主キーとなります。また、商品、ユーザー、日付を軸として見ることができます。
データを並べる
次に「ORDER BY」を用いてcountカラムを降順に並べて、10件SELECTしてください。
SELECT *
FROM `sample-90112.manabiba.sales`
ORDER BY count DESC
LIMIT 10
サンプルデータを見てもらうとわかりますが、order_idが昇順に並んでいます。「ORDER BY」を用いることでcountカラムが降順になるように並びました。
「ORDER BY」の並べ方は、昇順か降順を指定します。今回は降順のため「DESC」と指定しましたが、昇順に並べたい場合は「ASC」と指定してください。
レコード件数の取得
次は集計関数「COUNT」を使用して、レコード件数を確認してください。
SELECT COUNT(*) AS total
FROM `sample-90112.manabiba.sales` 
「COUNT( カラム名 )」とすることで、指定したカラムのデータの数を計算します。また、「カラム名 AS “名前”」で、カラム名に定義する名前を指定します。
70件のレコードがあることがわかります。 カラム数も6つ程なので、データとしては少ないですね。
特定のカラムのみ取得
最後は特定のカラムのみ確認してください。ここではuser_idを取得することにします。
SELECT user_id
FROM `sample-90112.manabiba.sales` 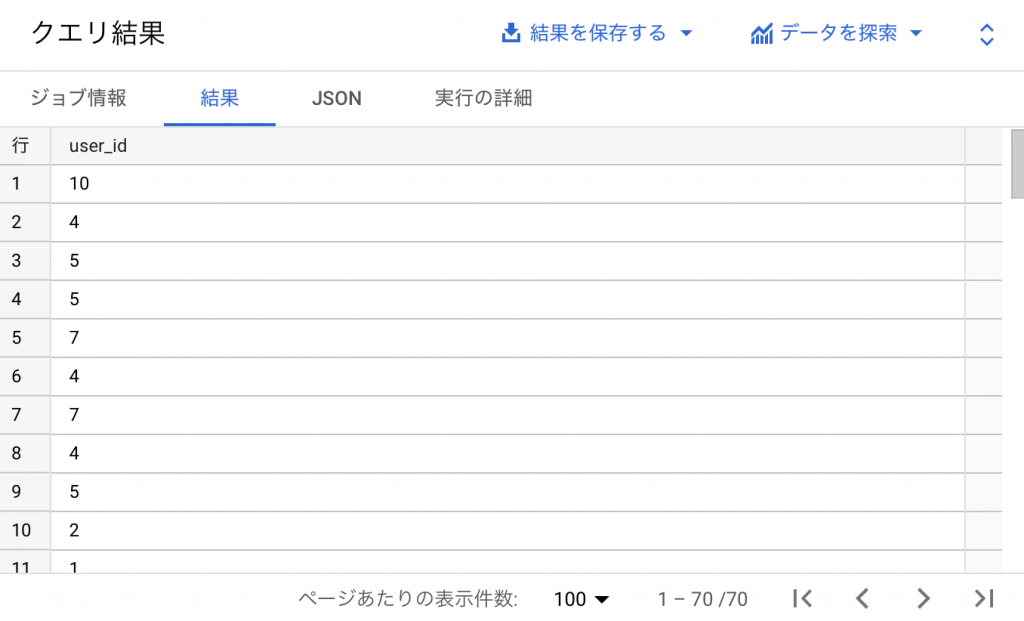
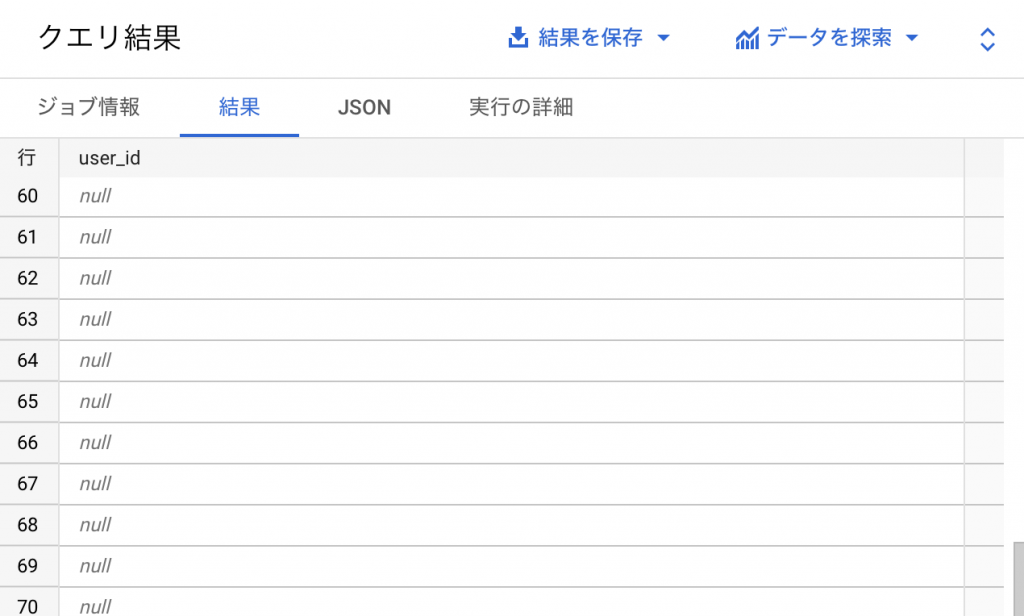
70件のuser_idが取得できます。また、10件のNULLがあり、欠損値が含まれていることがわかります。
まとめ
サンプルSQLのように生データを見ることで
- order_idとproduct_idで複合主キー
- 欠損値が含まれている
- 商品、ユーザー、日付が軸となり得る
といったことを先に把握でき、日付別に商品売上を分析してみたり、商品別に売上個数を分析してみたりといった、仮説に沿った分析方針を立てることができます。

コメント