
本記事の内容
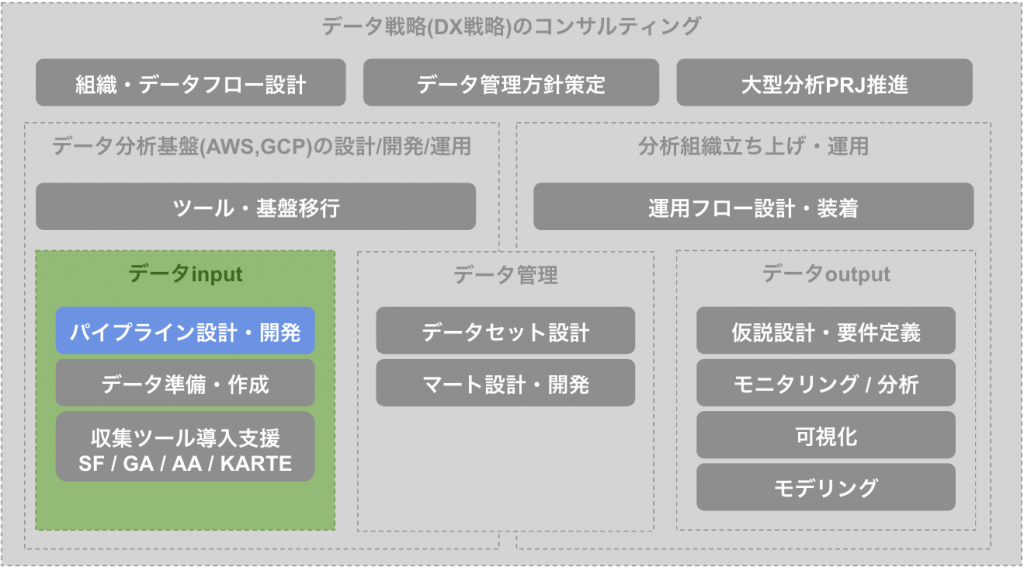
本記事では、Amazon RDSやAmazon DynamoDBからBigQueryにデータを連携するためのパイプライン設計をしていきます。
Amazon RDSやAmazon DynamoDBなどAWSのDB、ログを貯めておくストレージとしてAmazon S3を使っており、そのデータをGCPのBigQueryで分析したい場面があると思います。
- DBに直接ログインするのが面倒である
- DBのREADによってDBのリソースを使ってしまうためパフォーマンスが落ちる
- ログファイルを確認するのに工数がかかる
- いくつかデータソースに存在しているデータを統合してみたい
などの理由が考えられます。
成果物イメージ
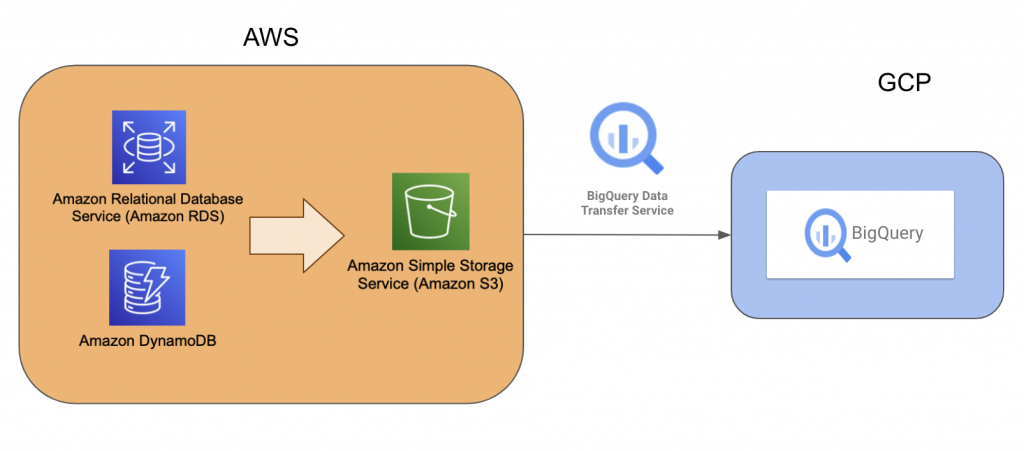
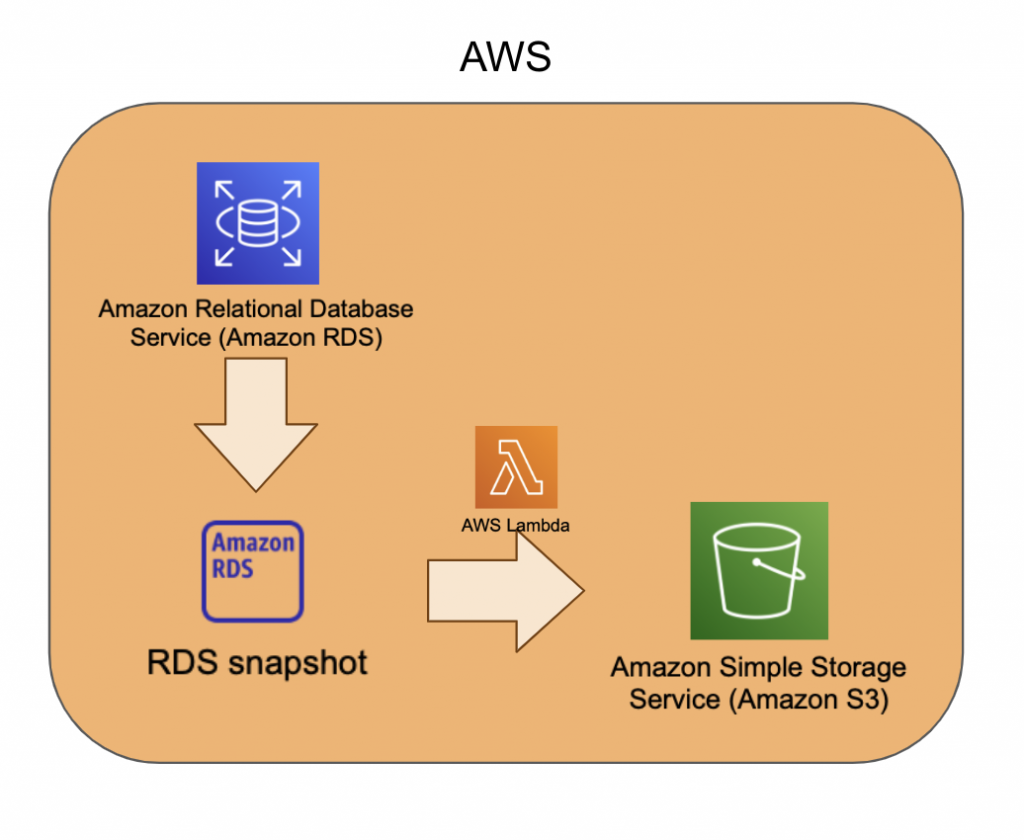
Amazon RDSやAmazon DynamoDBからAmazon S3を経由してBigQueryにデータを連携するためのパイプライン設計をしていきます。
Amazon S3からBigQueryへのデータ連携については、以下の記事にて実際のコードや手順も踏まえて紹介しておりますので、本記事では対象外とします。
想定要件
- Amazon RDSはMySQLを利用している。
- PostgreSQLの場合は、BigQuery でサポートされていない非標準のデータ型がMySQLより多いため、型に注意する必要があります。
- Amazon RDS、Amazon DynamoDBともにデータの作成・更新・削除がある。
- AWS側でのデータレイクとしてS3を利用する。
設計
Amazon DynamoDB
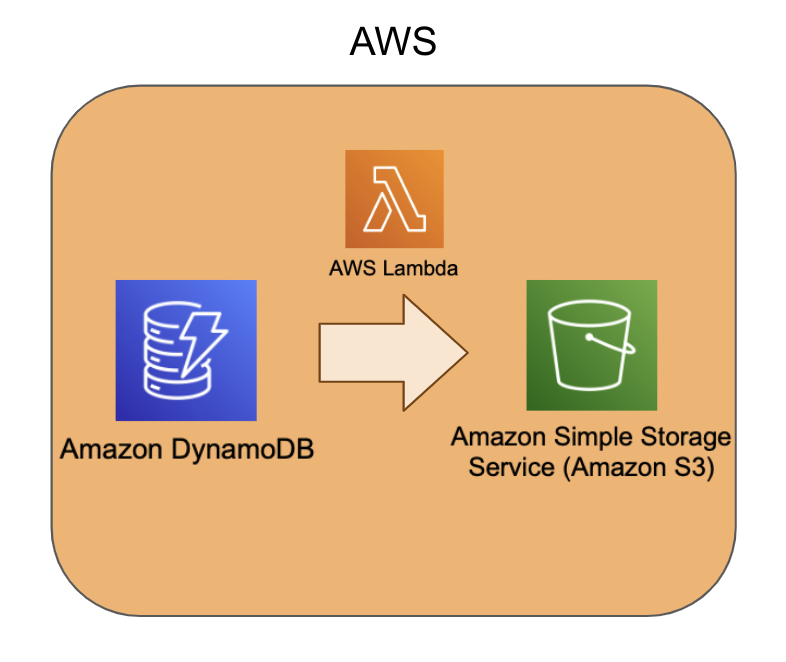
まずは、DyanmoDBに存在しているデータをAmazon S3に移行しましょう。
やり方は大きく3種類あります。
- コンソールからAmazon S3へのエクスポートを実行する
- AWS CLIからAmazon S3へのエクスポートを実行する
- おすすめ:Lambda(正確には、AWS SDK)からAmazon S3へのエクスポートを実行する
エクスポートを実行するためには、ポイントインタイムリカバリ (PITR)が有効になっている必要があります。
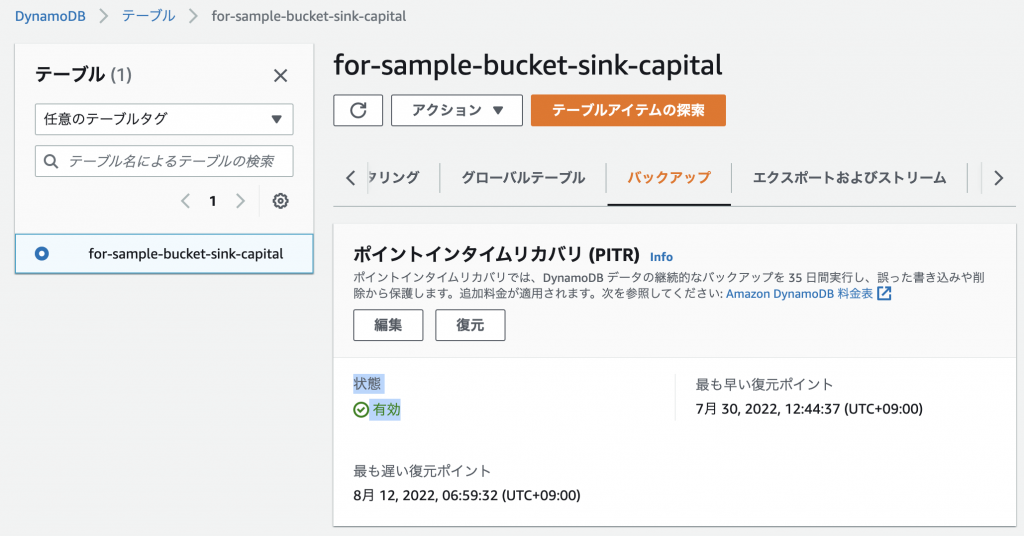
コンソール
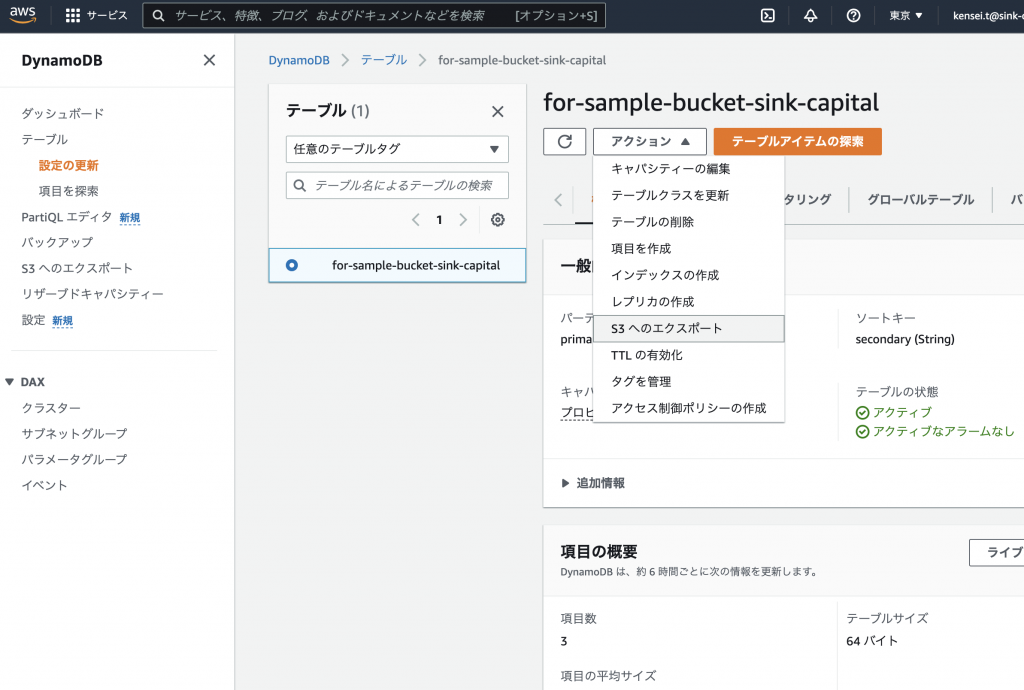
画像のようにAmazon DynamoDBのコンソールにてテーブルを選択し、「アクション」から「S3へのエクスポート」を選択します。
AWS CLI
AWS公式ドキュメントから引用します。
例:次のコマンドは、
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DataExport.Requesting.html#DataExport.Requesting.CLI2020-Novというプレフィックスが付いたddb-export-musiccollectionという S3 バケットにMusicCollectionをエクスポートします。テーブルデータは、ポイントインタイムリカバリウィンドウの特定の時点から DynamoDB JSON 形式でエクスポートされ、Amazon S3 キー (SSE-S3) を使用して暗号化されます。
aws dynamodb export-table-to-point-in-time \
--table-arn arn:aws:dynamodb:us-west-2:123456789012:table/MusicCollection \
--s3-bucket ddb-export-musiccollection \
--s3-prefix 2020-Nov \
--export-format DYNAMODB_JSON \
--export-time 1604632434 \
--s3-sse-algorithm AES256\AWS Lambda
この方法が一番おすすめです。理由は、2つあります。
1. 継続的なエクスポートの実行を実現しやすいこと
データ連携のパイプラインを作成するにあたり、継続的に連携を実施するケースが多いと思います。Amazon EventBridge(CloudWatch Events でも可能)を使用した AWS Lambda 関数のスケジュールを構築することで継続的なエクスポートの実行を容易に実現できます。

2. 実行環境への依存度が低い状態を構築するコストが低いこと
コンソールからの実行は人の作業を介する必要があります。
AWS CLIでの実行はcron化することができますが、実行するための環境としてローカル、もしくはCloudShellやEC2などを用意する必要があります。
それらの環境のメンテナンスの工数も考慮すると、サーバーレスサービスを用いるのが良いと考えられます。
AWS SDK v3 for JavaScript でAmazon DynamoDBからAmazon S3にエクスポートするコードも一応載せておきます。v2のコードは参考記事がたくさん見つかったのですが、v3のコードは見つけることができなかったので、参考になれば幸いです。
import {
DynamoDBClient,
ExportTableToPointInTimeCommand,
} from "@aws-sdk/client-dynamodb"; // ES Modules import
const client = new DynamoDBClient({ region: "ap-northeast-1" });
const DynamoDBTableArn = process.env.DYNAMODB_TABLE_ARN;
const ExportS3Bucket = process.env.EXPORT_S3_BUCKET;
export const handler = async (event) => {
const exportInput = {
TableArn: DynamoDBTableArn,
S3Bucket: ExportS3Bucket,
ExportFormat: "DYNAMODB_JSON",
};
// // aws sdk v2までは非同期処理のデフォルトはcallbackであり、Promiseで処理するには .promise() を使う必要がありました。
// await client.exportTableToPointInTime(exportInput).promise();
// aws sdk v3ではデフォルトでPromiseベースになりました。
// https://dev.classmethod.jp/articles/node-js-aws-sdk-v3/
// client.exportTableToPointInTime(exportInput, function (err, data) {
// if (err) console.log(err, err.stack); // an error occurred
// else console.log(data); // successful response
// });
const command = new ExportTableToPointInTimeCommand(exportInput);
const response = await client.send(command);
};Amazon RDS
次に、DyanmoDBに存在しているデータをAmazon S3に移行しましょう。Amazon DynamoDBとの違いは、バックアップの設定をして、スナップショットを作成する必要がある点です。
スナップショットの作成方法
DBの作成時の追加設定で、「自動バックアップを有効にします」にチェックをつけてください。バックアップの保持期間やメンテナンスウィンドウは特に用件がなければ、変更する必要がございません。
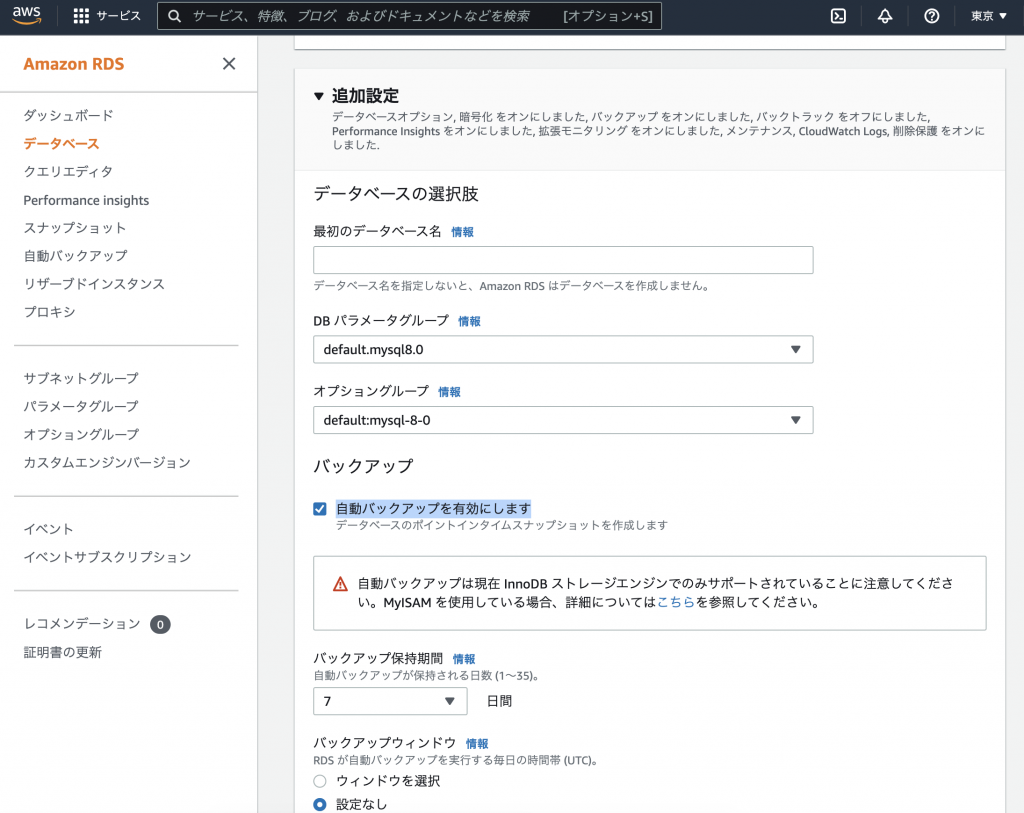
自動バックアップが有効であれば、毎日バックアップが実行され、スナップショットが作成されます。
また、手動(コンソール・CLI・SDK)でバックアップを実行することも可能です。任意のタイミングでバックアップを実行したい場合などは検討していただくと良いと思います。
スナップショットをAmazon S3にエクスポート
スナップショットが作成できたら、あとは基本的にDynamo DBと同じです。以下のいずれかの方法でスナップショットをAmazon S3にエクスポートしましょう。
- コンソールからAmazon S3へのエクスポートを実行する
- AWS CLIからAmazon S3へのエクスポートを実行する
- おすすめ:AWS Lambda(正確には、AWS SDK)からAmazon S3へのエクスポートを実行する
こちらも同様に、AWS SDK v3 for JavaScript でスナップショットをAmazon S3にエクスポートするコードを載せておきます。Amazon DynamoDBのコードと比較して、スナップショットの取得とエクスポートするスナップショットの選択のロジックがあるため少し長くなっております。
import {
DescribeDBSnapshotsCommand,
RDSClient,
StartExportTaskCommand,
} from "@aws-sdk/client-rds";
export const handler = async (event) => {
// 変数にしても良いが、リージョンくらいはハードコードでも良い。
const client = new RDSClient({ region: "ap-northeast-1" });
// 最新のSnapshotを取得
const command = new DescribeDBSnapshotsCommand({
// 変数にする。 DB_INSTANCE_IDENTIFIER
DBInstanceIdentifier: process.env.DB_INSTANCE_IDENTIFIER,
});
// console.log(command);
const describeResult = await client.send(command);
if (!describeResult.DBSnapshots) return;
const latestSnapshot = describeResult.DBSnapshots.sort(
// 降順に並び替えたい
(a, b) =>
(b.SnapshotCreateTime?.getTime() ?? 0) -
(a.SnapshotCreateTime?.getTime() ?? 0)
)[0];
const snapshotArn = latestSnapshot?.DBSnapshotArn;
if (!snapshotArn) return;
// snapshotの名前のみを取得したい
const snapshotName = snapshotArn.split(":").pop();
console.log(snapshotName);
// Exportをリクエスト
// 詳しくは👇のドキュメント
// https://docs.aws.amazon.com/AmazonRDS/latest/APIReference/API_StartExportTask.html
const exportCommand = new StartExportTaskCommand({
ExportTaskIdentifier: snapshotName,
// 👇コンソールからS3 Exportするときに作れるのでそれを使うのが楽
// 変数にする。 RDS_S3_EXPORT_ROLE_ARN
IamRoleArn: process.env.RDS_S3_EXPORT_ROLE_ARN,
// 変数にする。 S3_BUCKET_NAME
S3BucketName: process.env.S3_BUCKET_NAME,
// カスタムキーなら何でもよさそうだったけどDBの暗号化に使ってるキーにした
// 変数にする。 RDS_S3_EXPORT_KES_KEY_ID
KmsKeyId: process.env.RDS_S3_EXPORT_KES_KEY_ID,
SourceArn: snapshotArn,
});
return await client.send(exportCommand);
};また、Amazon DynamoDBでは必要なかったkms周辺の権限も必要となってくるため、適切なロールを設定してください。
まとめ
Amazon RDSやAmazon DynamoDBなどAWSのDBからAmazon S3への継続的なデータ連携パイプラインの設計について紹介しました。
本記事で紹介してアーキテクチャの特徴は、
- バックアップ機能などAWSが提供している機能を利用しているため(運用も含めて)コスパが良い設計を意識している。
- 代わりにデータ前処理などを挟むことができないなど柔軟性は低い。
となっております。
みなさまがプロジェクトの要件に適したパイプライン設計をする何かの参考に少しでもなれば幸いです。


コメント