
なぜデータマートが必要か
データマートの利点
利用部門ごとに使用するデータや分析内容が異なることが多いため、その利用部門が必要とするデータのみをデータウェアハウスから抽出したり、その利用部門が必要とする分析データをあらかじめ集計することにより、分析レスポンスを向上できる。これは、データ容量が小さくなることやリクエストのたびに集計値を計算することがなくなるためにレスポンスが向上できることと、通常は利用部門ごとにサーバを設置するためにサーバ単位の同時ユーザ数が減るためでもある。
https://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%9E%E3%83%BC%E3%83%88
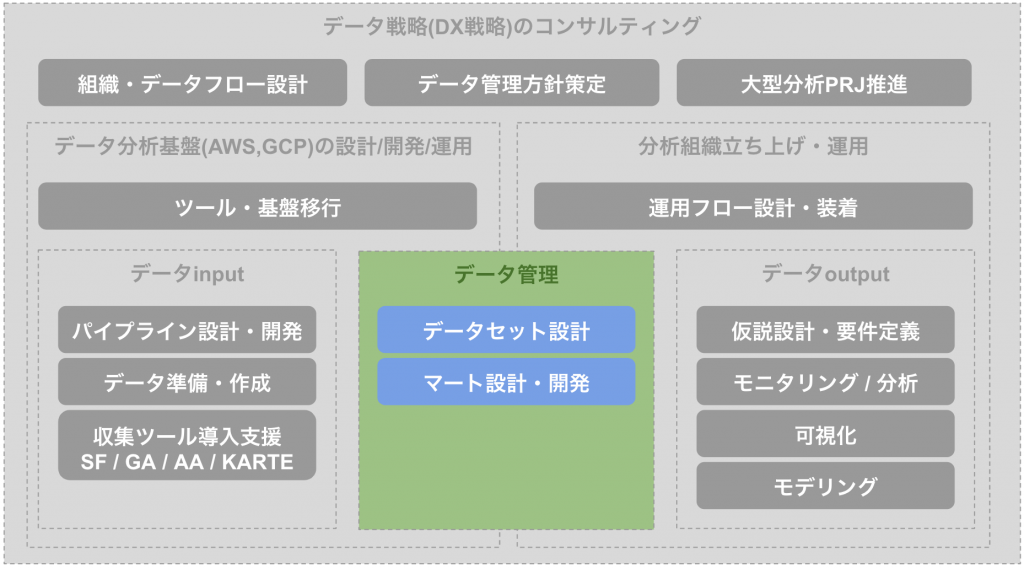
データマートは目的に沿って作られているため、上記のようにシステム的なレスポンス速度のメリットなどともに、利用者側がらのわかりやすさもメリットとしてあげられます。例えばアプリのシステムログの例でいうと、データマートだとログがテーブル形式でテーブルになっているだけなので集計するまで解釈が難しいですが、月次のエラー率のマートであればExcelなどと同じ感覚でそのまま解釈できる場合があります。また規模が大きい組織であればマート化することで、人によってデータの定義がずれづらいと言ったメリットも存在します。
dbtとは
Transforming data. Transforming teams.
dbt™ helps data teams work like software engineers—to ship trusted data, faster.
https://www.getdbt.com/
dbtはELTにおける(Transform)部分を担当するツールであり、Amazon RedshiftやGoogle BigQueryなどのクラウドDBに接続することでマートの作成処理等を行うことができます。BigQueryのscheduled queryやtroccoの機能でSQLを実行しマートを作ることはできますが、dbtはよりマート管理しやすい特徴が存在します
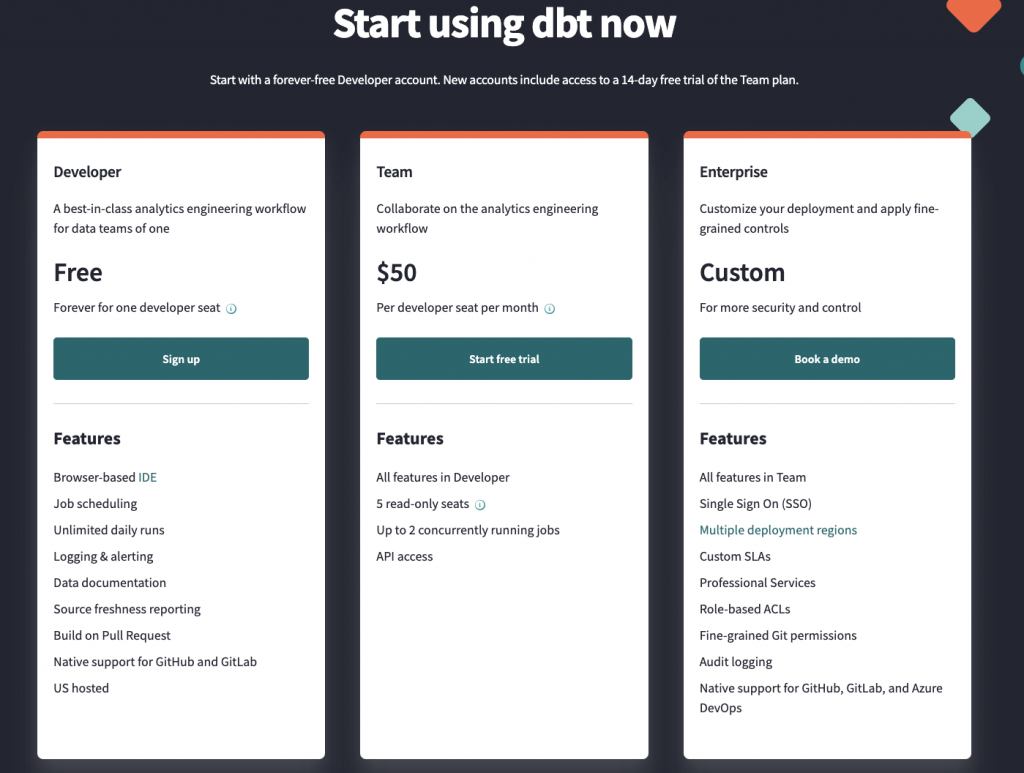
価格体系
dbtは3つの価格体系が存在し、それぞれ以下のような価格・特徴を持っています。今回は無料で用いることができるDevelopプランをベースに進めていこうと思います。
- Develop(Free):1人のみ利用可能
- Team($50 / developer / month):複数人でAPIも利用可能
- Enterprise(Custom / month):より詳細なセキュリティ管理が可能
dbtでできること
特徴
dbtの特徴としては以下のようなものがあげられます。
- オープンソースであり無料で利用することができる
- pythonやJinja2を組み合わせてSQL記法することができる
- 依存関係も貼ることができ、複雑なマート設計も可能
- Gitを利用してバージョン管理を行うことができる
GUIで操作がわかりやすくなっている一方でコードで設定を記述してGit管理されており、 利用者と管理者(エンジニア)両方にとって使いやすい印象を受けました。
チュートリアルの実施
利用開始方法
dbt cloudの利用開始方法は公式の Set up and connect BigQuery に記載がある通り、 dbtのアカウント作成後プロジェクトを作成して必要事項を埋めていくことで開始することができます。
- dbt cloudのサイトから「Create a free account」をクリックし、メアド等を入力してアカウント作成を行います
- 「connect your datawarehouse」から「BigQuery」の接続情報を入れていき、dbt内部のプロジェクトを作成します
- サンプルのリポジトリが作成され、利用開始できる状態になります
サンプルの設定の編集方法
利用開始時点ですでにフォルダ構成が出来上がっているため、 いくつかのファイルを編集することで使い始めることができます。 マートやviewを作る上では最低限以下2つを編集すればできます。
- 設定ファイル:
dbt_ptoject.yml - SQLファイル:
models/**.sql
設定ファイル
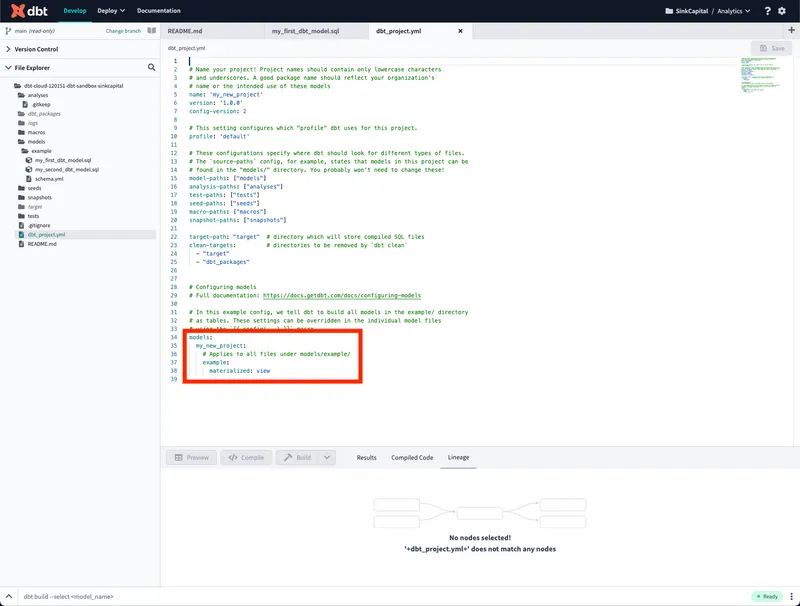
設定ファイルは主に添付画像の赤枠内の models 配下を編集する必要があります。 今回は主にデータセット名を変えつつデフォルトは物理テーブルを作成するように変更します。
models:
dbt_ysakurai: # ここを編集することでデータセット名を変えることができます
materialized: table # デフォルトで物理テーブル or Viewどちらを作るか設定できます
example:
materialized: view # ここでexampleフォルダ配下の設定を行いますデプロイ
このようにconfigとSQLを編集した後、画面下のコンソールから dbt run を実行することでBigQueryに反映することができます。 またJobsを設定することでスケジュール実行を行うこともできます。その他に dbt docs 系のコマンドによってドキュメントの作成及び閲覧もできるはずですが、 dbtの依存関係周りのエラー(No matching handler found for rpc method None (which=serve))が出るため、 解消でき次第記事に追記させていただければと思います。
既存ツールとの比較
最後にTransform箇所で利用可能な他の既存ツールとの比較を行おうと思います。
| 手段 | メリット | デメリット |
|---|---|---|
| scheduled query | ・管理サーバー不要 ・スケジュール実行可能 ・サービス料金無料 | ・ジョブ依存管理不可 ・数が増えると管理困難 ・SQLで行える処理のみ実行可能 |
| Cloud Run | ・複雑なジョブ実行可能 ・スケジュール実行可能 ・比較的安価に利用可能 | ・ジョブ依存管理不可 ・数が増えると管理困難 |
| Cloud Composer (Airflow) | ・ジョブ依存管理可能 ・スケジュール実行可能 | ・学習コストが高い ・$400~/月程度のインフラ費用 |
| trocco | ・ELTのすべて対応可能 ・ジョブ依存管理可能 ・スケジュール実行可能 | ・10万~/月程度のインフラ費用 |
| dbt cloud | ・ジョブ依存管理可能 ・スケジュール実行可能 ・無料から利用可能 | ・学習コストが少しあり |
簡易的な比較ですが「ジョブ依存・スケジュール実行が安価にできる」が大きな特徴としてあげられそうです。
まとめ
今まで小さな組織では一旦scheduled queryから開始することが多かったですが、 今後はdbtを用いて初期の段階からジョブ依存も貼れるワークフローを導入することが選択肢として入ってくると思われます。 その際はGit周りなどの学習コストが必要となるため、 運用する組織のスキルセットに合わせて選択していく形になるかと思われます。

コメント